写在之前:此文翻译自:https://peteris.rocks/blog/htop,做了少许改动,感谢原作者。
长久以来,我只知Linux有个神器htop,却不知道htop的各项指标的内涵。
比如,2核的服务器 CPU利用率为 50%,那为啥load average 却显示 1.0?那接下来开始捋捋。。。
俗话说得好,好记性不如个烂笔头。
Htop on CentOS
来个htop全身照:

- Uptime
uptime:系统运行的时长。
当然,你可以用uptime:
|
|
uptime从 /proc/uptime文件获取信息:
|
|
前者数字(9592411.58)代表系统运行的秒值,后者(9566042.33)代表服务器空闲秒数。一般多核系统后者秒值会比系统的uptime值大,因为它是取和。作者是怎么知道这个原因的呢?通过跟踪 uptime 程序运行打开的文件,这里是用的 strace 工具:
|
|
从strace输出中grep查找系统调用的open 函数。由于strace标准输出内容较多,可以使用2>&1重定向:
|
|
其中,包括前面提到的 /proc/uptime文件。这说明我们可以使用 strace -e open uptime来代替strace uptime 2>&1 | grep open。Linux的uptime命令提供易读、宜用的方法。
- Load average
除了uptime,有三个数字表示 load average:
|
|
load average值是从 /proc/loadavg文件获得,同时你也可以用 strace 验证。
|
|
前三个数字分别表示最近1分钟、5分钟、15分钟的CPU和IO的利用率。第四行显示当前正在运行的进程数和进程总数,最后一行显示最近使用的进程ID。
下面讲下进程ID。当你启动一个新进程,它将会分到一个ID数字。进程ID通常是递增的,除非进程退出后进程ID重新复用。特殊进程ID 1 是属于/sbin/init ,系统启动时即分配。
让我们再来看下 /proc/loadavg文件的内容,然后后台启动 sleep 命令,这时会输出进程ID。
|
|
所以,1/123 代表一个进程正在运行,总共有123个进程运行过。
当运行cat /dev/urandom > /dev/null (重复生成随机数)时,你会发现有 2 个进程在运行:
|
|
这里的两个进程是:随机数生成、cat /proc/loadavg,同时load average值也在增加。
System load average是runnable或uninterruptable状态的进程数的平均数。所以上面的 load average为 1(平均1个运行的进程),是因为作者演示的服务器是单核CPU,一次跑一个进程那CPU的利用率是100%。如果服务器是双核,那CPU利用率就是50%。双核CPU的利用率如果是100%,那load average 将会是2.0。CPU的核数可以从htop的左上角看到,或者运行 nproc。
- Processes
在htop的右上角显示进程数和多少个进程正在运行。但是htop使用 Tasks 代表进程(注:Tasks 是进程的一个别名)。
在htop中,使用键盘上的Shift+H组合键也可轻松看到线程数Tasks: 23, 10 thr,使用Shift+K组合键可以看到内核线程数,Tasks: 23, 40 kthr。
- Process ID / PID
每个进程启动都会分配一个唯一的进程ID,称作进程ID或者PID。如果你在bash中使用 (&)在后台执行,你将会看到输出的PID。
|
|
如果你手滑没看到,那也可以在bash中使用 $!内建变量查看到最近一次后台运行的PID:
|
|
进程ID是非常有用的,具体为什么可以看维基百科。
procfs是伪文件系统,procfs可以让用户的程序通过读取文件的方法从Linux内核中获取信息。它经常被挂载在 /proc/下,伪装的看起来像个正规文件目录,你也可以使用 ls 和 cd命令。
某进程相关的所有信息都放在 /proc/<pid>/下:
|
|
比如, /proc/\
|
|
正确的查看姿势是(因为命令是用\0 分隔):
|
|
或者:
|
|
进程的进程目录还包含有链接(link),比如: cwd指向工作目录,exe指向可执行的二进制文件:
|
|
以上就是htop,top, ps这些诊断工具是为啥可以获取到一个进程的详细信息的,/proc/\
- Process tree
在htop中使用F5 即可看到进程树,当然也可以用ps f:
|
|
或者 pstree
|
|
从这里你就可以知道为啥 bash 或者 sshd 是其它进程的父进程。
/sbin/init 作为系统启动进程,进程ID为1,接着是SSH的守护进程 sshd(当你用ssh连接到服务器),接着是 bash shell。
- Process user
每个进程属于一个user,user以数值ID代表:
|
|
可以用id命令发现更多关于此user的信息:
|
|
通过如下证明id是从/etc/passwd 和 /etc/group 文件获取信息的:
|
|
查看/etc/passwd 和 /etc/group 文件的内容:
|
|
passwd文件内没有密码,那密码存储在哪里呢?实际存在/etc/shadow
|
|
如果你想以root用户来运行程序,得用sudo:
|
|
如果你想登录到另外一个用户并启动各种命令,使用sudo bash 或者 sudo -u user bash。
当你不想输入密码登录服务器,则可以增加user到 /etc/sudoers 文件。
|
|
你会发现只有root用户可以操作。
|
|
咋回事呢?还是不行。。。
当你以root权限执行echo命令追加一行到/etc/sudoers ,仍然使用的原user。
通常有两种解决方法:
echo "$USER ALL=(ALL) NOPASSWD: ALL" | sudo tee -a /etc/sudoerssudo bash -c "echo '$USER ALL=(ALL) NOPASSWD: ALL' >> /etc/sudoers"
第一种,tee -a追加标准输入到文件,这时执行以root权限;
第二种,我们以root用户执行bash,用 (-c) 以root执行整个命令。注意双引号/单引号,因为 $USER变量转义的问题。
当你想更改密码时,可用 passwd,也可用 /etc/shadow 文件,这个文件必须用root权限:
|
|
passwd 如何才能被常规user执行往具有保护权限的文件写入?
当你启动一个进程时,那这个进程属于你的用户,即使这个可执行文件的拥有者是其它user。
你能改变文件的权限:
|
|
注意 s 字符,它是sudo chmod u+s /usr/bin/passwd实现的,意味着能以拥有者root的身份运行可执行文件。
你使用 find /bin -user root -perm -u+s会发现一个setuid 可执行文件。同理,对用户组可以用 (g+s)。
- Process state
接下来看下htop中进程状态列,其用字母 S 表示。
下面是进程列的可能取值:
| R | 运行状态(running)或者运行队列中的就绪状态(runnable) |
|---|---|
| S | 中断睡眠(等待事件完成) |
| D | 非中断睡眠(常为IO) |
| Z | 僵尸进程,无效进程但是未被父进程回收 |
| T | 被控制信号停止 |
| t | 跟踪时被调试者停止 |
| X | 死亡状态 |
注意,当你运行ps时,它将也会显示子状态,比如Ss,R+,Ss+,等等.
|
|
R - 运行状态或者运行队列中的就绪状态
在这种状态下,进程正在运行或者在运行队列中等待运行。
那运行的都是啥呢?
当你编译所写的源代码,生成的机器码是CPU指令集,并保存为可执行文件。当你启动程序时,该程序被加载进内存,然后CPU执行这些指令集。
从根本上来说,CPU是在执行指令,换句话说,处理数字。
S - 中断睡眠
这意味着该进程的指令不能在CPU上立即执行。相反地,该进程等待某个事件或者条件发生。当事件发生,系统内核设置进程状态为运行状态。
本例是GNU的coreutils软件包中的sleep工具。它将睡眠指定秒数。
|
|
所以这是一个中断睡眠。那如何中断该进程?通过发送控制信号。
你能在 htop 中点击 F9 ,然后在左侧菜单中选择一个信号发送。
发送的信号中最有名的是kill。因为kill是一个系统调用,其能发送信号给进程。程序/bin/kill能从用户空间做系统调用,默认的信号是使用TERM,该信号要求进程中止或者杀死。
信号其实只是一个数字,但是数字太难记住,所以我们常说对应的名字。信号名字用大写表示,并用SIG前缀。
常用的信号有INT, KILL, STOP, CONT, HUP。
让我们发送INT(也称作,SIGINT或者2或者 Terminal interrupt )中断睡眠。
|
|
当你在键盘上敲击CTRL+C 也会产生上面同样的效果。 bash 将发送前台进程 SIGINT 信号。
顺便提一下,在 bash中,虽然大部分操作系统都有 /bin/kill ,但是 kill 是一个内建命令。这是为什么呢?如果你创建的进程达到限制条件,它允许进程被kill。
实现相同功能的命令:
kill -INT 10089kill -2 10089/bin/kill -2 10089
另外一个有用的信号是 SIGKILL (也被称作 9)。你可以使用该信号kill掉不响应的进程,省的你发狂的按 CTRL+C 键盘。
当编写程序时,你能设置信号handler函数,该函数将在进程收到信号时被调用。换句话说,你能捕获信号,然后做点什么事。例如,清理或者优雅的关闭进程。所以发送 SIGINT 信号(用户想中断一个进程)和SIGTERM (用户想中止一个进程)并不意味着进程被中止。
当你运行Python脚本,你会发现一个意外:
|
|
你可以告诉内核强制中止一个进程,使用发送 KILL信号:
|
|
D - 非中断睡眠
不像中止睡眠进程那么简单,你不能用信号唤醒该进程。这就是为什么许多人喊怕看到这个状态。你不能kill该进程,因为kill意味着通过发送SIGKILL 信号给该进程。
如果进程必须等待不中断或者事件被期望快速发生,那这个状态被使用,比如读写磁盘。但是这仅仅发生一秒分之一。
引用自StackOverflow
不中断进程经常等到I/O出现页缺失(page fault)。进程/任务不能在这种状态下中断,因为它不能处理任何信号;如果中断了,另外一个页缺失将会发生,会返回到原始位置。
换句话说,如果你在使用NFS(网络文件系统)时出现中断,那得好久才恢复。
或者,以我的经验看,意味着进程正在交换许多小内存。
让我们试着一个进程进入不中断睡眠。
8.8.8.8 是Google提供的公共DNS服务。他们没有一个开放的NFS,但是也不能阻止试验。
|
|
如何找出刚才发生了什么? strace!
strace上面ps的输出命令:
|
|
所以 mount 系统调用正在阻塞进程。
如果想看看发生了什么,你能运行带intr 选项的 mount 命令来中断: sudo mount 8.8.8.8:/tmp /tmp -o intr。
Z - 僵尸进程,无效进程但是未被父进程回收
当一个进程以 exit退出时,它还有子进程,此时子进程变成了僵尸进程。
- 如果僵尸进程存在一小会,那相当正常;
- 僵尸进程存在很长时间可能导致程序bug;
- 僵尸进程不消耗内存,仅仅是一个进程ID;
- 僵尸进程不能被
kill; - 发生
SIGCHLD信号能让父进程回收僵尸进程; kill僵尸进程的父进程能摆脱父进程和其僵尸进程
下面写个C程序的例子展示下:
|
|
安装GNU C编译器(GCC):
|
|
编译代码并运行:
|
|
查看进程树:
|
|
我们得到了僵尸进程。当父进程退出,僵尸进程也退出。
|
|
如果用while (true) ; 代替 sleep(20) ,僵尸进程将正常退出。
使用exit时,该进程所有的内存和资源被释放,其它的进程可以继续使用。
为什么要保留僵尸进程存在呢?
父进程使用 wait系统调用找出其子进程退出码(信号 handler)。如果一个进程睡眠,它需要等待唤醒。
为什么不简单的强制进程唤醒和kill掉?当你厌倦小孩时,你不会把他扔垃圾桶。这里的原因相同。坏事情总会发生的。
T - 被控制信号停止
打开两个终端窗口,使用 ps u能查看到用户的进程:
|
|
忽略 -bash 和ps u进程。
现在在其中一个终端窗口运行cat /dev/urandom > /dev/null 。其进程状态为 R+ ,意味着正在运行。
|
|
按 CTRL+Z 停止该进程:
|
|
该进程的状态现在为 T。
在第一个终端运行 fg 可以重新恢复该进程。
另外一种停止进程的方法是用 kill 发送 STOP 信号给进程。然后使用 CONT 信号可让进程恢复执行。
t - 跟踪时被调试者停止
首先,安装GNU调试器(gdb):
|
|
监听网络端口1234的入网连接:
|
|
状态显示睡眠状态,那意味着该进程在等待网络传入数据。
|
|
运行调试器,并与进程ID为3905的进程关联:
|
|
你会发现这个进程的状态变为t,这意味着调试器正在跟踪该进程。
|
|
- Process time
Linux是一个多任务的操作系统。这意味着,即使机器只有一个PCU,也能在同一个时间点运行多个进程。你可以通过SSH连接服务器查看 htop 输出,同时你的web服务也在通过网络传输博客内容给读者。
那系统是如何做到在单个CPU上一个时间点只执行一个指令呢?答案是时间共享。
一个进程运行“一点时间”,然后挂起;这时另外一个等待的进程运行“一点时间”。进程运行的这“一点时间”称为时间片(time slice)。
时间片通常是几毫秒。所以只要服务器系统的负载不高,你是注意不到的。
这也就可以解释为什么平均负载(load average)是运行进程的平均数了。如果你的服务器只有一个核,平均负载是1.0,那CPU的利用率达到100%。如果平均负载高于1.0,那意味着等待运行的进程数大于CPU能承载运行的进程数。所以会发现服务器宕机或者延迟。如果负载小雨1.0,那意味着CPU有时会处于空闲状态,不做任何工作。
这也给你一个提示:为什么一个运行了10秒的进程的运行时间有时会高于或者低于准确的10秒。
- Process niceness and priority
当运行的task数比可用的CPU核数要多时,你必须找个方法决定接下来哪个task运行哪个task保持等待。这其实是 task scheduler的职责。
Linux内核的scheduler负责选择运行进程队列中哪个进程接下来运行,依赖于内核使用的scheduler算法。
一般你不能影响scheduler,但是让它知道哪个进程更重要。
Nice值(NI) 是表示用户空间进程优先级的数值,其代表静态优先级。Nice值的范围是-20~+19,拥有Nice值越大的进程的实际优先级越小(即Nice值为+19的进程优先级最小,为-20的进程优先级最大),默认的Nice值是0。Nice值增加1,降低进程10%的CPU时间。
priority(优先级,PRI)是Linux内核级的优先级,其代表动态优先级。该优先级范围从0到139,0到99表示实时进程,100到139表示用户空间进程优先级。
你可以改变Nice值让内核考虑该进程优先级,但是不能改变priority。
Nice值和priority之间的关系如下:
|
|
所以 PR = 20 + (-20 to +19) 的值是0到39,映射为100到139。
在启动进程前设置该进程的Nice值:
|
|
当程序已经正在运行,可用 renice改变其Nice值:
|
|
下面是CPU使用颜色代表的意义:
蓝色:低优先级线程(nice > 0)
绿色:常规优先级线程
红色:内核线程
- 内存使用 - VIRT/RES/SHR/MEM
进程给人的假象是只有一个进程使用内存,其实这是通过虚拟内存实现的。
进程没有直接访问物理内存,而是拥有虚拟地址空间,Linux内核将虚拟内存地址转换成物理内存或者映射到磁盘。这就是为什么看起来进程能够使用的内存比电脑真实的内存要多。
这里说明的是,想准确计算一个进程占用多少内存并不是那么直观。你也想计算共享内存或者磁盘映射内存吗?htop 显示的一些信息能帮助你估计内存使用量。
内存使用颜色代表的意义:
绿色:Used memory
蓝色:Buffers
橘黄色:Cache
VIRT/VSZ - 虚拟内存
task使用的虚拟内存总量。它包含代码、数据和共享内存(加上调出内存到磁盘的分页和已映射但未使用的分页)。
VIRT 是虚拟内存使用量。它包括所有的内存,含内存映射文件。
如果应用请求1GB内存,但是内存只有1MB,那 VIRT显示1GB。如果 mmap映射的是一个1GB 文件, VIRT也显示1GB。
大部分情况下, VIRT并不是一个太有用的数字。
RES/RSS - 常驻内存大小
task使用的非交换的物理内存。
RES是常驻内存使用量。
RES相比于 VIRT,能更好的表征进程的内存使用量:
不包含交换出的内存;
不包含共享内存
如果一个进程使用1GB内存,并调用fork()函数,fork的结果是两个进程的 RES 都是1GB,但是实际上只使用了1GB内存。因为Linux采用的是copy-on-write机制。
SHR - 共享内存大
task使用的共享内存总量。
简单的反应进程间共享的内存。
|
|
|
|
|
|
MEM% - 内存使用量占比
task当前使用的内存占比。
该值为 RES 除以RAM总量。
如果 RES 是400M,你有8GB的RAM,MEM% 是 400/8192*100 = 4.88%。
“庖丁解牛”式问诊Linux启动全过程
本文使用Digital Ocean droplet Ubuntu服务器启动过程为“蓝本”,详细解说Linux启动涉及的所有进程。
Ubuntu系统引导启动的进程都有哪些?你都需要它们吗?
下面是在全新Digital Ocean droplet 的Ubuntu(16.04.1 LTS x64)服务器上启动系统。
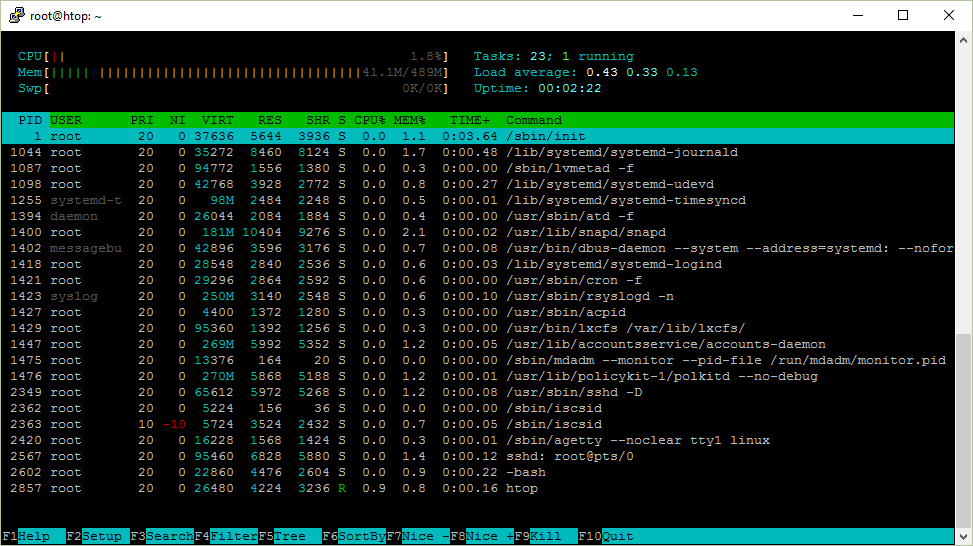
- /sbin/init
/sbin/init程序,也称init,调度除boot进程外所有的进程,配置用户环境。
init启动后,将成为所有系统自动启动进程的父进程或者祖父进程。
它是systemd吗?
|
|
答案是,yes。
如果kill掉/sbin/init会发生什么呢?什么也不会发生,哈哈。
- /lib/systemd/systemd-journald
systemd-journald进程是一个系统服务,其收集、存储log数据。它基于接收的log信息创建和维护结构化、索引journal。
换句话讲。
journald主要的变化之一,是采用优化的log存储替代简单文本log文件。使得系统管理员访问相应的log信息更有效。journald引入数据库式log的集中存储能力。
你可以使用 journalctl 命令查询log文件。
|
|
相当酷有木有!
看起来不能移除或者disable该服务,但是你可以关闭logging。
- https://www.freedesktop.org/software/systemd/man/systemd-journald.service.html
- https://www.digitalocean.com/community/tutorials/how-to-use-journalctl-to-view-and-manipulate-systemd-logs
- https://www.loggly.com/blog/why-journald/
- https://ask.fedoraproject.org/en/question/63985/how-to-correctly-disable-journald/
- /sbin/lvmetad -f
lvmetad守护进程缓存LVM元数据(metadata),所以LVM命令不用扫描磁盘就能读取元数据。
元数据缓存的优势,在于扫描磁盘是非常耗时的,并且可能中断系统和磁盘的正常工作。
那什么才是LVM(Logical Volume Management,逻辑卷管理)呢?
你可以认为逻辑卷管理LVM是动态分区(dynamic partitions),意味着你能在正在运行的系统上用命令行创建/重设大小/删除(create/resize/delete)LVM分区(用LVM的话讲是逻辑卷):无须重启操作系统来让内核感知新建或者重设大小的分区。
听起来像,如果你正在使用LVM服务,那得保留该服务。
|
|
- /lib/systemd/udevd
systemd-udevd监听Linux内核uevent事件(uevent是内核空间和用户空间之间通信的机制,主要用于热插拔事件(hotplug))。对于每个事件,systemd-udevd都会根据udev规则执行匹配的指定设备。
udev是Linux内核的设备管理器。其作为devfsd和hotplug的升级,udev主要管理/dev目录下的设备节点。
所以该服务会管理 /dev。
作者不太确定是否一定要运行在虚拟机上。
- /lib/systemd/timesyncd
systemd-timesyncd是使用远程网络时间协议来同步本地系统时钟的系统服务。
所以该服务是来替代ntpd的。
|
|
查看一下服务器上打开的端口:
|
|
以前在Ubuntu 14.04上打开的端口如下:
|
|
https://www.freedesktop.org/software/systemd/man/systemd-timesyncd.service.html
- /usr/sbin/atd -f
atd将作业加入队列稍后执行。atd通过
at将业务加入队列。
at和批量从标准输入输出或者指定文件读命令并稍后执行。
cron命令调度作业周期性重复运行,at只在指定时间运行一次。
|
|
不需要使用的话可以卸载:
|
|
- /usr/lib/snapd/snapd
Snappy Ubuntu Core是带有事务性更新的Ubuntu版本,其和当前的Ubuntu具有相同的library的最小服务器镜像,但是以更简单的机制来提供应用。
很显然,它是一个简化版的deb包,分发的所有依赖都在单个snap中。
作者从来不用snappy在服务器上发布或者分发应用,所以可以卸载:
|
|
- /usr/bin/dbus-daemon
在计算机中,D-Bus或者DBus是进程间通信( inter-process communication,IPC)和远程过程调用(remote procedure call,RPC)机制,它允许在同一台机器上并发运行的多个计算机程序(进程)通信。
作者觉得当你需要桌面环境时要启动该服务,当你只是在服务器上运行web应用则可以卸载:
|
|
然而,当你想看下时间是否通过NTP同步,发现了问题:
|
|
- /lib/systemd/systemd-logind
systemd-logind是管理用户登录的系统服务。
- /usr/sbin/cron -f
cron守护进程执行调度计划命令。
-f保持运行在前台,不以守护进程运行。
你可以使用cron周期性调度任务运行。
crontab -e 编辑cron的配置文件,在Ubuntu上可以用 /etc/cron.hourly,/etc/cron.daily等配置。
你可以使用下面的方法查看cron的log文件:
grep cron /var/log/syslogjournalctl _COMM=cronjournalctl _COMM=cron --since="date" --until="date"
如果你不想使用cron时,可以停止并disable该服务:
|
|
当使用 apt remove cron 删除cron服务时,会发现其会安装postfix:
|
|
看起来cron服务需要邮件客户端(MTA)发送邮件:
|
|
- /usr/sbin/rsyslogd -n
Rsyslogd是提供消息日志的系统组件。
换句话说,rsyslogd将日志写入 /var/log/ 目录下,比如 /var/log/auth.log 是SSH登陆的权限日志。
rsyslogd的配置文件是/etc/rsyslog.d。
你也可以配置rsyslogd发送log文件到远程服务器,实现日志log中心化。
你也可以在后台脚本中使用 logger 命令将消息日志写入 /var/log/syslog 。
|
|
但是,前面已经有 systemd-journald 服务在运行了,那还需 rsyslogd 吗?
Rsyslog 和 Journal服务是存在于系统中的两个log日志应用,它们功能不同。大部分情况下,需要同时结合两者的功能。比如,创建结构化的消息并存储到文件数据库。通信接口需要Rsyslog提供输入和输出模块,通信socket由Journal提供。
所以呢?看样子还是暂时保留吧。
- http://manpages.ubuntu.com/manpages/xenial/man8/rsyslogd.8.html
- http://manpages.ubuntu.com/manpages/xenial/man1/logger.1.html
- https://wiki.archlinux.org/index.php/rsyslog
- https://www.digitalocean.com/community/tutorials/how-to-centralize-logs-with-rsyslog-logstash-and-elasticsearch-on-ubuntu-14-04
- https://access.redhat.com/documentation/en-US/Red_Hat_Enterprise_Linux/7/html/System_Administrators_Guide/s1-interaction_of_rsyslog_and_journal.html
- /usr/sbin/acpid
acpid,是高级配置与电源接口(Advanced Configuration and Power Interface,ACPI)事件守护进程。
acpid设计用来通知ACPI事件的用户空间程序,其在系统启动时已启动,并默认以后台进程运行。
计算机中的高级配置与电源接口,提供处理电源相关事件的开源标准。操作系统可以处理计算机硬件的发现和配置,可以进行电源管理。比如,将未使用的组件置为睡眠,进行状态监控。
但是本例中使用的虚拟机,不需要挂起/继续。
这里删除该服务,看下会发生什么。
|
|
作者可以成功执行 reboot重启 droplet,但是执行 halt 后必须通过web接口关闭虚拟机。
- /usr/bin/lxcfs /var/lib/lxcfs/
Lxcfs主要是以lxc容器为用户提供fuse文件系统。在Ubuntu 15.04上,默认提供两个功能:一是,一些/proc文件的视图;二是,过滤访问主机的cgroup文件系统。
总之,在Ubuntu 15.04上你能用通用的方式( lxc-create)创建容器。创建的容器使用uptime、top等能得出“正确”结果。
不用LXC容器时可以移除该服务:
|
|
- /usr/lib/accountservice/accounts-daemon
账户管理AccountsService包提供一系列D-Bus接口查询和管理用户账户信息。其是基于usermod(8),useradd(8) 和userdel(8) 命令实现的。
作者想知道移除该服务会出现什么问题。当移除DBus时, timedatectl失效。
|
|
- /sbin/mdadm
Linux组件mdadm是管理RAID设备的管理和监控软件。
其名字是源于md(multiple device,多设备)节点管理(administers),它替代之前的mdctl。原始的名字是 “Mirror Disk”,随着功能的增加名字随之改变。
RAID是将多块硬盘看作是一块硬盘的方法。RAID的目的有两个:1)扩展磁盘驱动容量:RAID 0。如果你有2个500GB的HDD,则总的容量即为1TB;2)防止驱动失败时数据丢失。比如RAID 1,RAID 5, RAID 6和RAID 10。
可以用如下命令移除:
|
|
- /usr/lib/policykit-1/polkitd –no-debug
polkitd:PolicyKit守护进程。
polkit:授权管理。
有点类似是细粒度的sudo权限控制。你能允许非权限用户做某些root用户的操作。比如,桌面计算机中的Linux重启计算机。
这里是运行的服务器,可以移除该服务:
|
|
- /usr/sbin/sshd -D
sshd(OpenSSH Daemon),ssh的守护进程。
指定-D选项时,sshd不断开,也不成为守护进程。这样会更容易监控sshd。
- /sbin/iscsid
iscsid是系统守护进程,处理iSCSI配置和管理连接。从帮助页看到:
iscsid实现iSCSI协议的控制路径,和一些设备管理。比如,守护进程能配置成在服务器启动时自动重启,该功能基于持久化iSCSI数据库。
可以移除该服务:
|
|
- /sbin/agetty –noclear tty1 linux
agetty是alternative Linux getty的缩写。
getty,是”get tty”的简写,通常从
/etc/inittab启动,允许用户从终端 (TTYs)登录。它会提示输入用户名,运行’login’ 程序授权用户登录。早期getty存在传统Unix系统,其管理一系列连接到主机上的终端(电传打字机,Teletype machine)连接。其中tty是Teletype的缩写,后来代指各种文字终端。
如果在物理服务器上,你可以使用getty登录。在Digital Ocean,你可以点击droplet详情上的Console,通过浏览器和终端交互(可能是VNC连接)。
在过去,系统启动后你会看到一大泼tty启动(一般配置在/etc/inittab);不过现在都用systemd代替。
下面移除 agetty启动的配置文件:
|
|
然后重启服务器,仍然可以通过SSH连接服务器,但是不能通过Digital Ocean的web控制台登录服务器啦。

- sshd: root@pts/0 & -bash & htop
sshd: root@pts/0 意味着root用户在#0伪终端 (pts)创建啦SSH会话。
bash 是指使用的shell。
但是为啥bash 开头有个破折号呢?Reddit上有解释:
bash开头的破折号是因为bash以login shell模式启动时(取得bash时需要完整的登录流程)。启动login shell模式有两种方式:使用“-”参数启动;使用”—login”选项启动。它们都会加载配置文件。
htop 是交互式进程查看工具。
接着移除下面的服务:
|
|
用htop查看会出现如下图:

再次挑战“极限”情况:
|
|
再用htop查看:

未完待续。。。
Enjoy!
侠天,专注于大数据、机器学习和数学相关的内容,并有个人公众号:bigdata_ny分享相关技术文章。
若发现以上文章有任何不妥,请联系我。
